Leaving the Integration Services SSISDB Database on a SQL instance after Integration Services has been removed can cause the SQL Database service to fail to start after the next SQL Server Cumulative Update installation.
Uninstalling the Integration Services component through the Add / Remove programmes > “Microsoft SQL Server 20xx (64-bit)” Uninstall wizard, as encouraged by Microsoft here, will leave the SSISDB database present on the instance, setting the fuse for SQL startup failure and a late night support call in your next SQL instance patching window.
The feature removal wizard also leaves the logins, maintenance jobs, and any other components within the SQL Server instance.
Leaving the SSISDB database from an uninstalled Integration Services database on a SQL instance will likely prevent the instance from starting after the next SQL Cumulative Update installation due to the Cumulative Update post-install startup script attempting to upgrade the no-longer-installed SSIS component when it sees the SSISDB database.
Here’s an example updating from SQL Server 2019 CU21 to SQL Server 2019 CU22 instance with a SSIS Catalog database (SSISDB) present. For reference, this catalog doesn’t contain any packages. This is a test catalog with no packages, but pretend all the packages have been removed ahead of uninstalling the SSIS feature for the purposes of this demo.
How to disable a SQL Database Instance while following the standard Microsoft processes
Do these steps without first removing the SQL Services Integration Services catalog, and your instance won’t start after a standard SQL Server Cumulative Update.
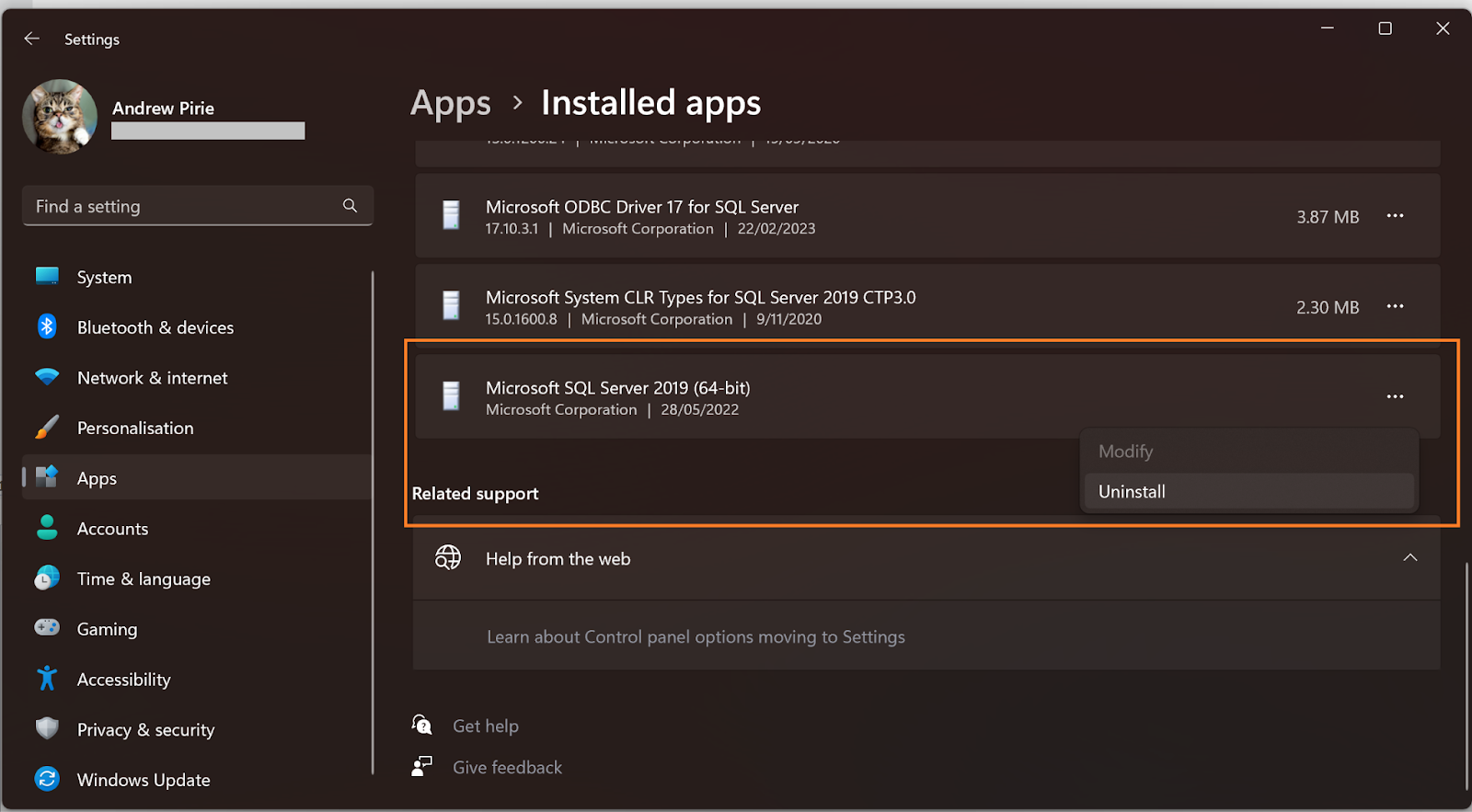
Navigate to Add/Remove Apps and select to uninstall Microsoft SQL Server 20xx (x64-bit)
Select the Remove option
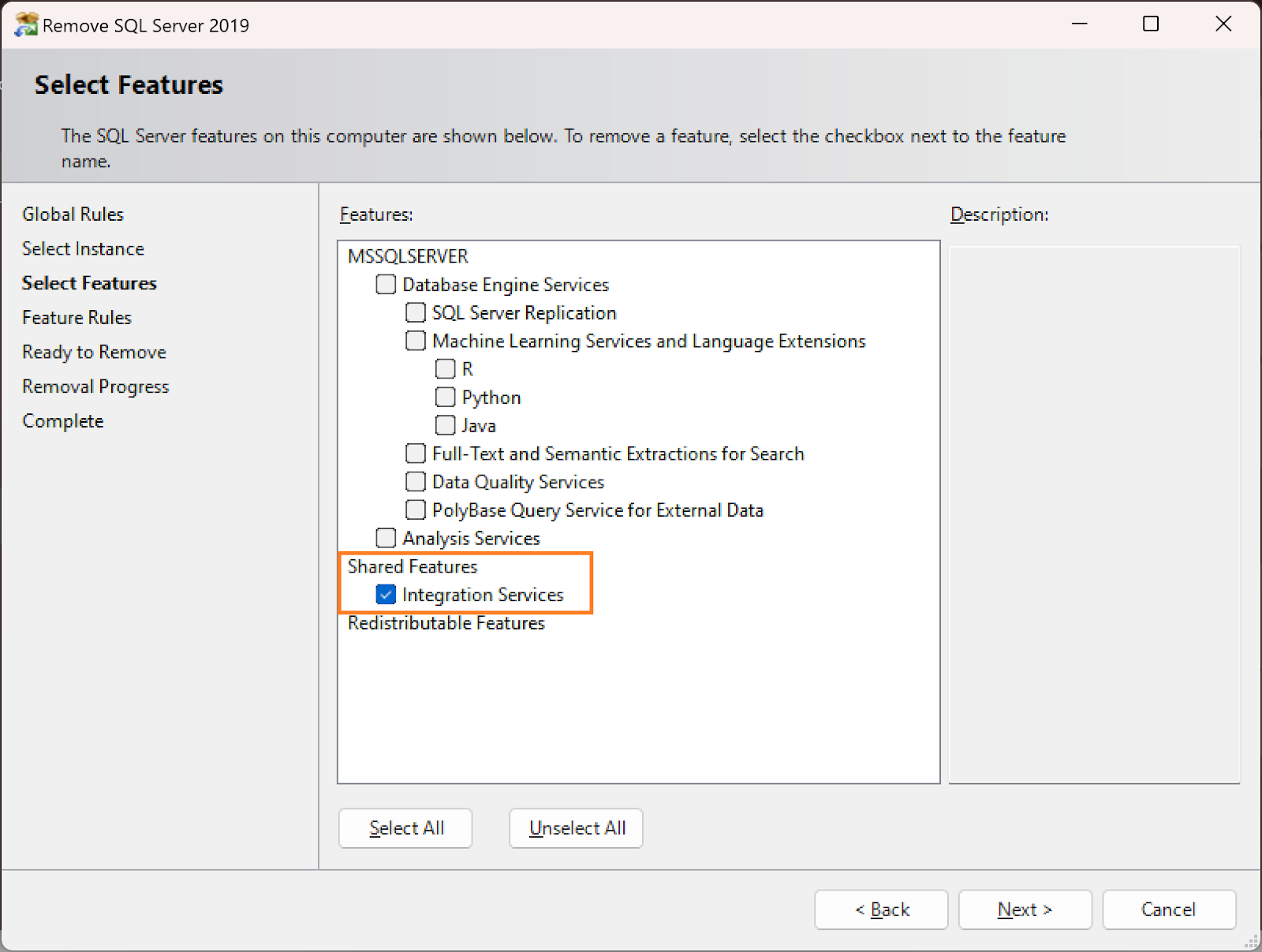
Select the instance to remove the Integration Services feature from
Select to remove the Integration Services feature
Select Remove to start the uninstallation of the Integration Services feature while leaving the other components installed.
Close the feature installation wizard.
- Restart the server if you do that after making configuration changes.



Mission accomplished. All looks well. Book closed?
Now restart the server, and apply a Cumulative Update. If the Cumulative Update happens to include an Integration Services update, which may not be the one installed immediately after you uninstalled the Integration Services component, you’re in for fun.
Install a Cumulative Update like normal. Here I’ve jumped a few updates, going from CU21 to the latest (CU22).
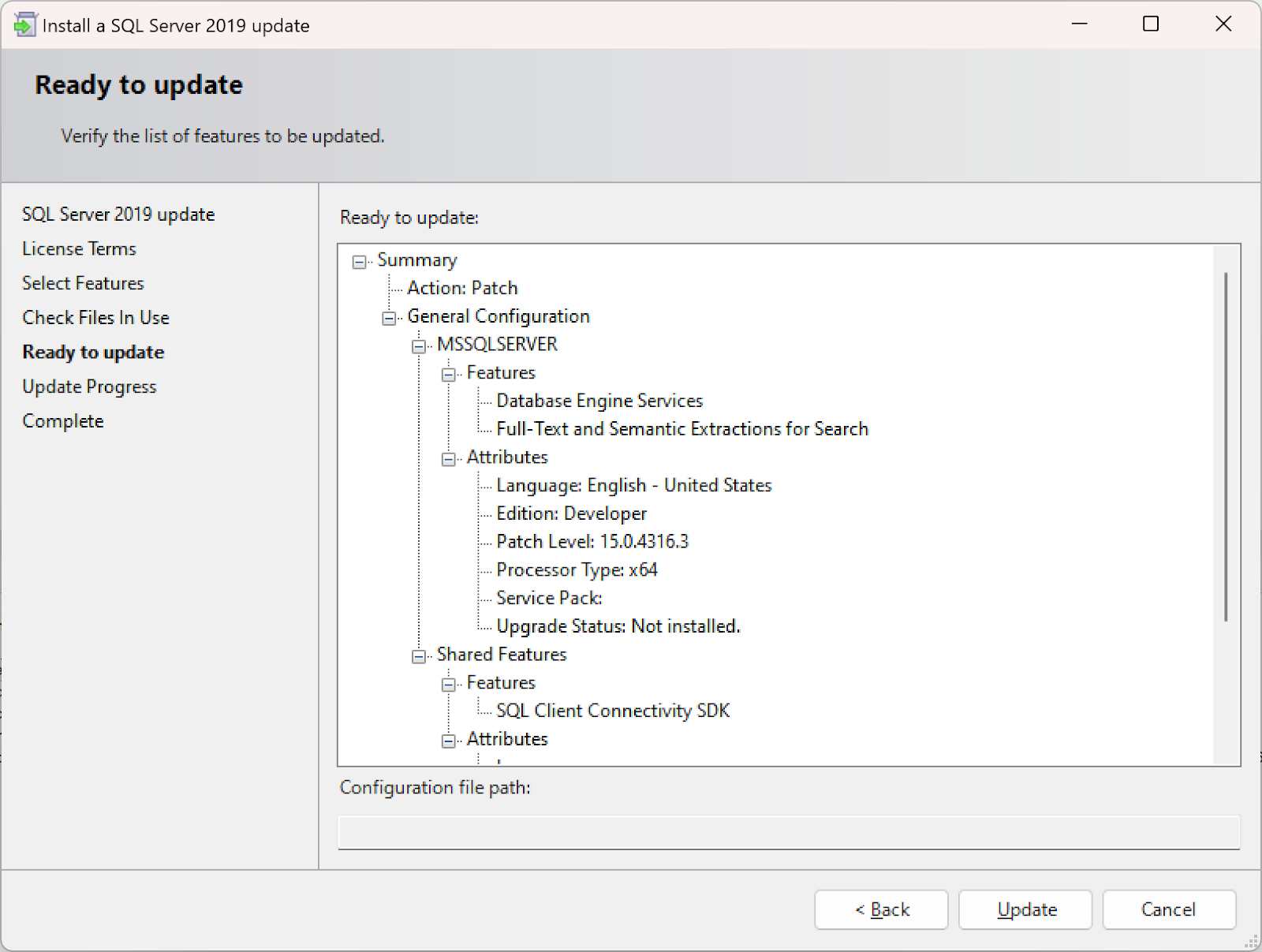
Here’s the Cumulative Update failure when updating from CU21 to CU22
Error details:
■ Error installing SQL Server Database Engine Services Instance Features
Wait on the Database Engine recovery handle failed. Check the SQL Server error log for potential causes.
Error code: 0x851A001A
Visithttps://go.microsoft.com/fwlink?LinkId=20476&ProdName=Microsoft+SQL+Server&EvtSrc=setup.rll&EvtID=50000&ProdVer=15.0.4322.2&EvtType=0xD15B4EB2%400x4BDAF9BA%401306%4026&EvtType=0xD15B4EB2%400x4BDAF9BA%401306%4026 to get help on troubleshooting
Here’s the behavior with the same process followed but updating from CU18 to CU22.
The SQL Server ERRORLOG file (under Program Files\Microsoft SQL Server\<Instance>\Log) ends with the following message:
2023-10-05 20:56:53.31 spid9s Error: 3417, Severity: 21, State: 3.
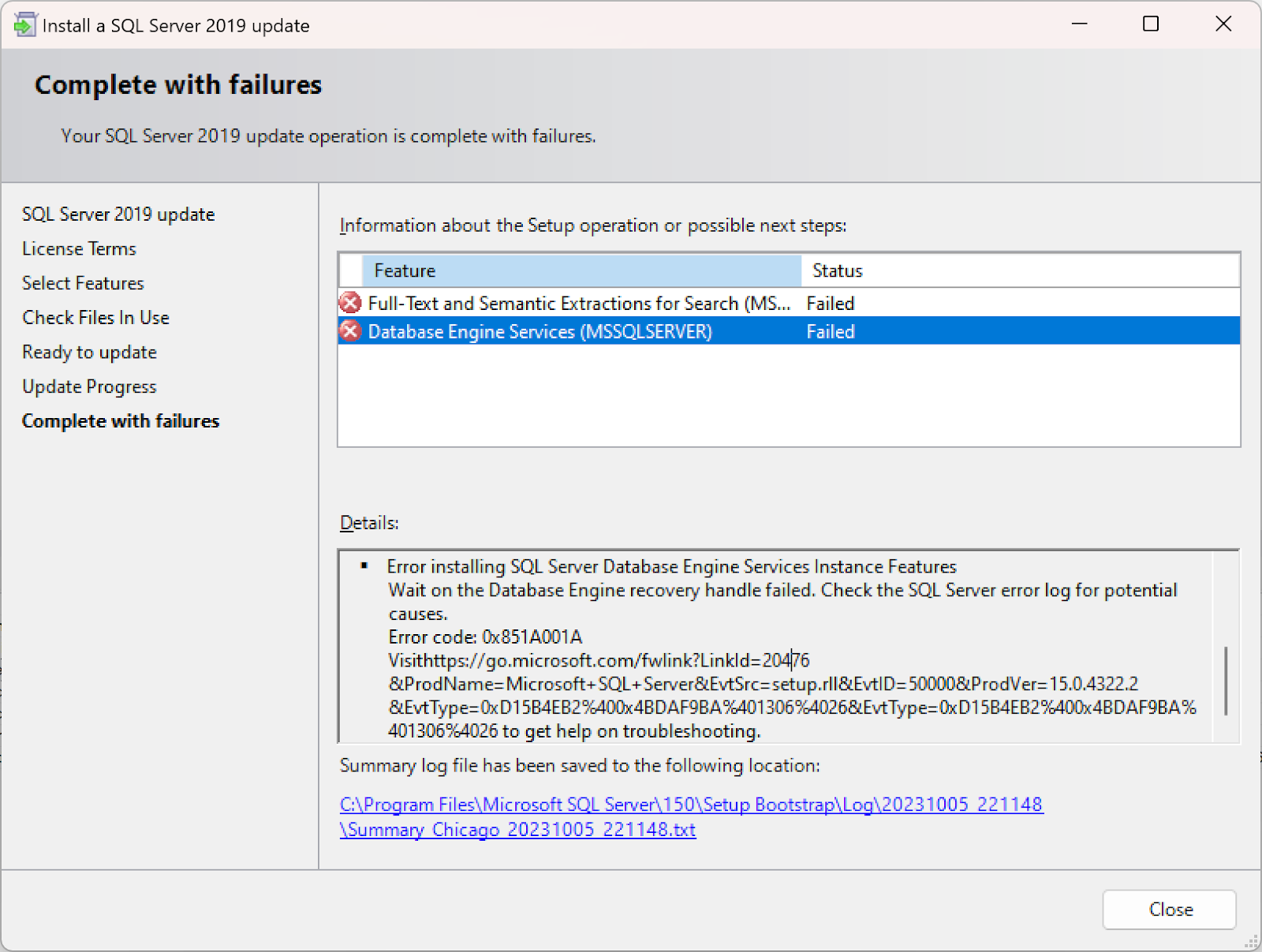

2023-10-05 20:56:53.31 spid9s Cannot recover the master database. SQL Server is unable to run. Restore master from a full backup, repair it, or rebuild it. For more information about how to rebuild the master database, see SQL Server Books Online.
This error occurs because a final piece in the Cumulative Update process is to restart the SQL Server Database service to run the database upgrade scripts for the build-in databases.
Attempting to SQL Server Database Service manually also fails, with the below error.
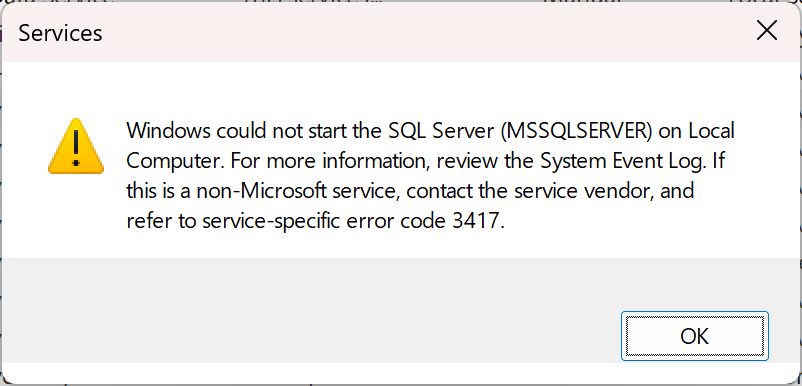
Re-checking the ERRORLOG file shows a repeat of the above “Cannot recover the master database” error.
The preceding steps give the key hint at why the master database script failed:
<standard database service startup logs>
Error: 18401, Severity: 14, State: 1.
Login failed for user 'NT SERVICE\SQLServerReportingServices'. Reason: Server is in script upgrade mode. Only administrator can connect at this time. [CLIENT: <named pipe>]
0 transactions rolled back in database 'SSISDB' (16:0). This is an informational message only. No user action is required.
Recovery is writing a checkpoint in database 'SSISDB' (16). This is an informational message only. No user action is required.
Parallel redo is shutdown for database 'SSISDB' with worker pool size [6].
Starting up database 'tempdb'.
The tempdb database has 8 data file(s).
The Service Broker endpoint is in disabled or stopped state.
The Database Mirroring endpoint is in disabled or stopped state.
Service Broker manager has started.
Database 'master' is upgrading script 'ISServer_upgrade.sql' from level 0 to level 500.
---------------------------------------------
Starting execution of ISServer_upgrade.SQL
---------------------------------------------
Taking SSISDB to single user mode
Setting database option SINGLE_USER to ON for database 'SSISDB'.
CREATE NONCLUSTERED INDEX [index_tasks_ReadyForDispatchTime] ON [internal].[tasks] ([ReadyForDispatchTime] ASC) INCLUDE ([CreatedTime], [CreateWorkerAgentId], [ExecutedCount], [ExpiredTime], [InputData], [IsCritical], [JobId], [LastUpdatedTime], [MaxExecutedCount], [Priority], [Status], [TaskType]) WITH (ONLINE = ON)
CREATE NONCLUSTERED INDEX [index_tasks_Status] ON [internal].[tasks] ([Status]) INCLUDE ([ExecutedCount], [ExpiredTime], [IsCancelled], [MaxExecutedCount], [WorkerAgentId]) WITH (ONLINE = ON)
The module 'prepare_execution' depends on the missing object 'internal.set_system_informations'. The module will still be created; however, it cannot run successfully until the object exists.
The module 'encrypt_data' depends on the missing object 'internal.create_key_information'. The module will still be created; however, it cannot run successfully until the object exists.
The module 'deploy_packages' depends on the missing object 'internal.deploy_packages_internal'. The module will still be created; however, it cannot run successfully until the object exists.
The module 'start_execution' depends on the missing object 'internal.start_execution_internal'. The module will still be created; however, it cannot run successfully until the object exists.
The module 'stop_operation' depends on the missing object 'internal.stop_operation_internal'. The module will still be created; however, it cannot run successfully until the object exists.
---------------------------------
Starting assembly upgrade
---------------------------------
Altering assemly [ISSERVER]
Attempting to load library 'xpstar.dll' into memory. This is an informational message only. No user action is required.
Using 'xpstar.dll' version '2019.150.4322' to execute extended stored procedure 'xp_regread'. This is an informational message only; no user action is required.
Error: 50000, Severity: 16, State: 127.
Cannot bulk load. The file "C:\Program Files\Microsoft SQL Server\150\DTS\Binn\Microsoft.SqlServer.IntegrationServices.Server.dll" does not exist or you don't have file access rights.
Error: 50000, Severity: 16, State: 127.
Cannot bulk load. The file "C:\Program Files\Microsoft SQL Server\150\DTS\Binn\Microsoft.SqlServer.IntegrationServices.Server.dll" does not exist or you don't have file access rights.
Creating function internal.is_valid_name
Error: 6528, Severity: 16, State: 1.
Assembly 'ISSERVER' was not found in the SQL catalog of database 'SSISDB'.
Error: 912, Severity: 21, State: 2.
Script level upgrade for database 'master' failed because upgrade step 'ISServer_upgrade.sql' encountered error 6528, state 1, severity 16. This is a serious error condition which might interfere with regular operation and the database will be taken offline. If the error happened during upgrade of the 'master' database, it will prevent the entire SQL Server instance from starting. Examine the previous errorlog entries for errors, take the appropriate corrective actions and re-start the database so that the script upgrade steps run to completion.
Error: 3417, Severity: 21, State: 3.
Cannot recover the master database. SQL Server is unable to run. Restore master from a full backup, repair it, or rebuild it. For more information about how to rebuild the master database, see SQL Server Books Online..
At this stage, you have a SQL Server instance that won’t start. Using the command line parameters for minimal, single-user mode (-f -m) don’t help.
Every time the SQL Server Database Services starts, it attempts to run the database upgrade scripts, including the SSISDB database, which no longer contains the special loaded SQLCLR assemblies required to run SSIS - that feature is no longer installed.
Here's how to fix this.
To recover from this state and bring the instance back online, re-install the SQL Server Integration Services feature from a SQL Server installation media as you would when adding a new feature. This will allow the SQL database service to start.
Note if you don’t have access to the installation media for the installed SKU, you should be able to use the Developer Edition media for this step.
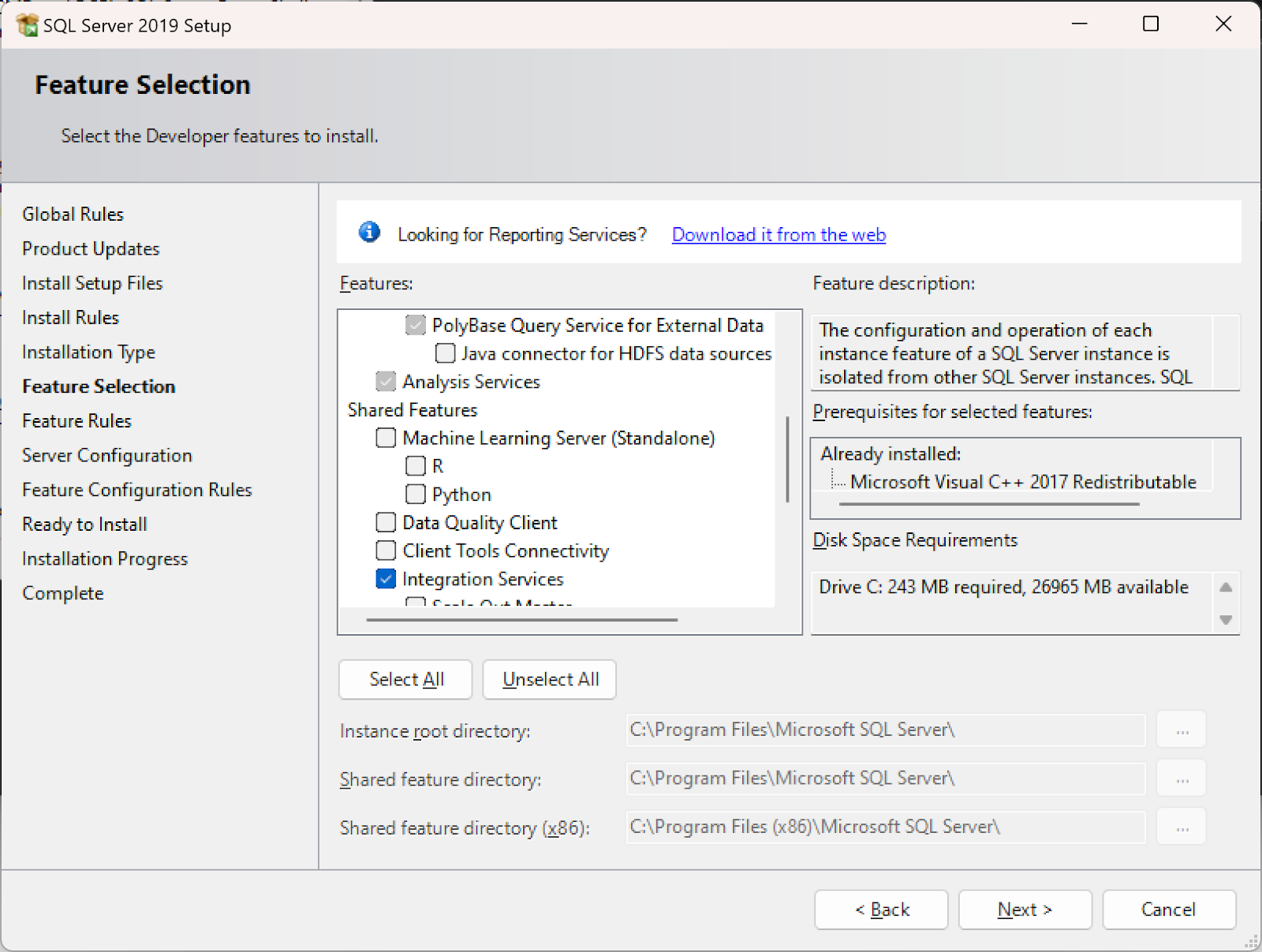

Once Integration Services is re-installed, manually start the SQL Server service if it isn’t running, and re-connect using a client tool. If you get the message that the machine is in script update mode, wait for a while - in my test machine it took a couple of minutes - and try to connect again.
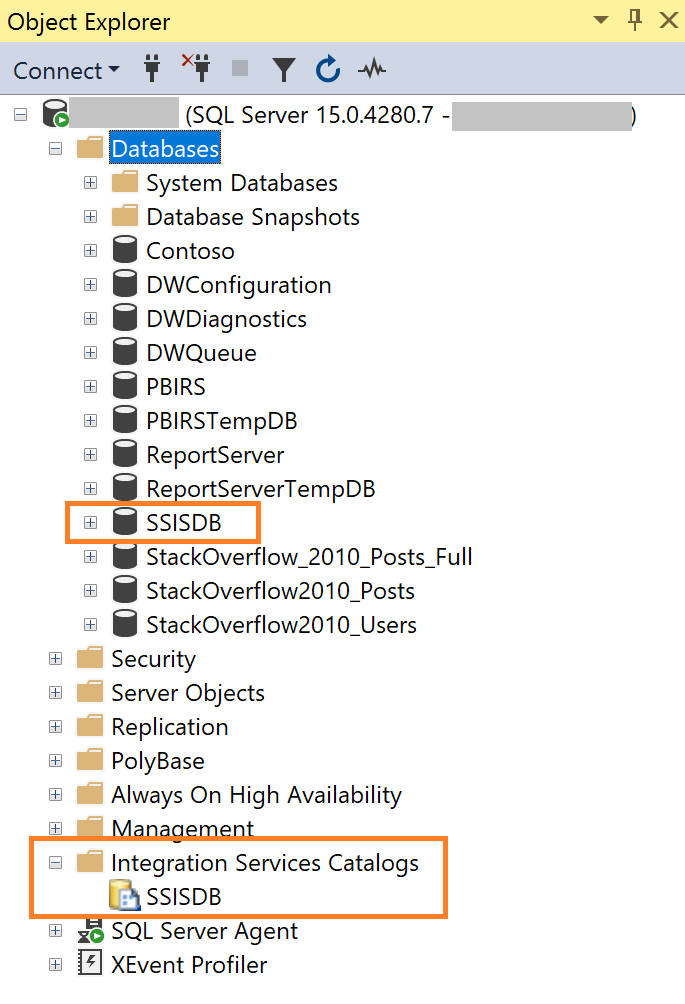
Once connected, expand Integration Services Catalogs, right-click SSISDB, and select Delete.

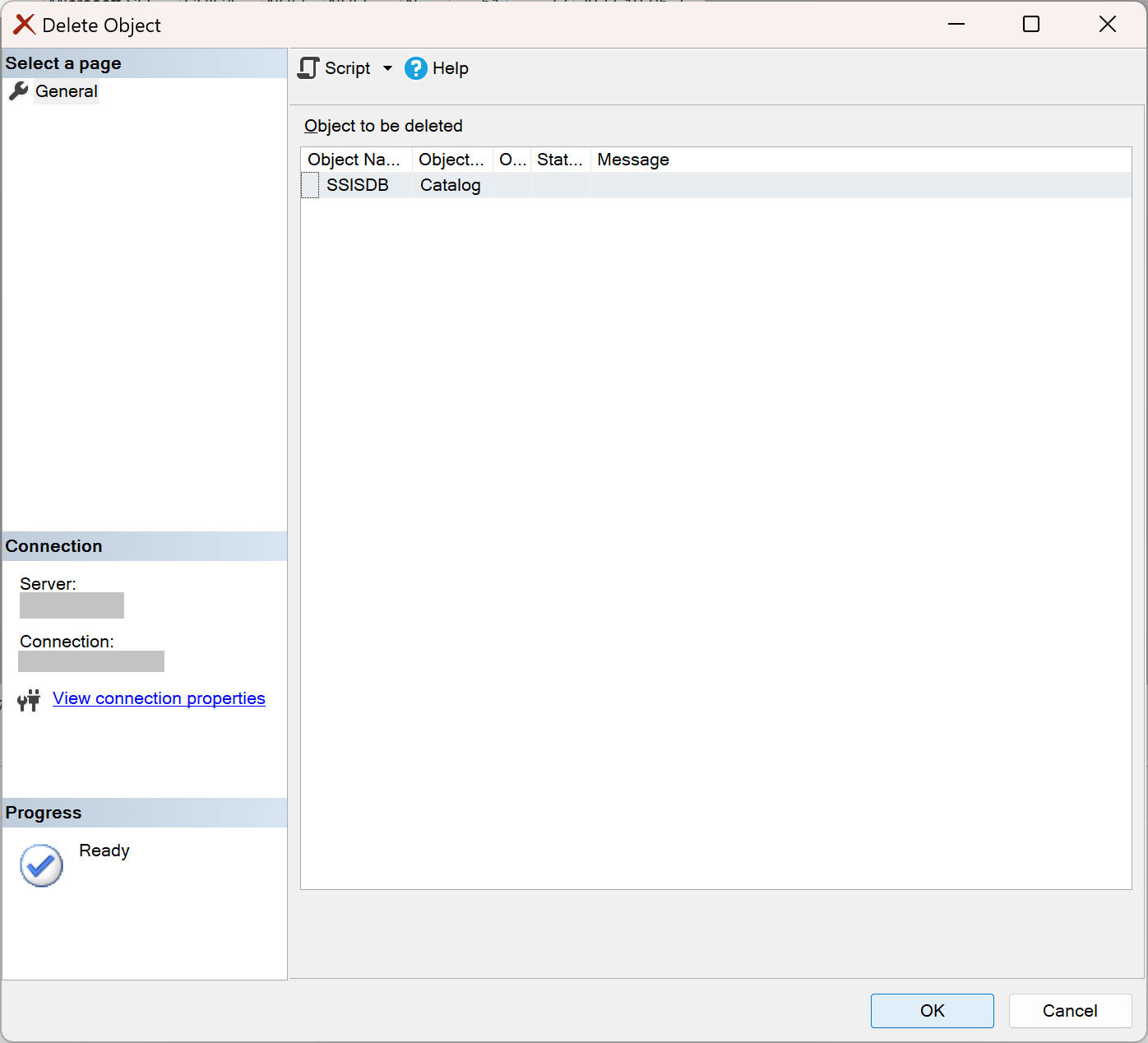
With the SSISDB catalog removed, you can safely uninstall the Integration Services component using the above steps. With the database removed, you can also have confidence that the next Cumulative Update experience will be smoother.
Watching XEvent Profiler while the catalog is deleted via Management Studio, it does a few actions - removing any SSIS startup procedure, maintenance jobs, SQL logins for the maintenance jobs, drops the SQLCLR assemblies from the SSISDB database, and finally drops the SSISDB database itself. None of this happens when the feature is removed via the Control Panel > Add / Remove Apps > remove feature path, even if that path looks to be supported.